Human and environment sensing are two important topics in Computer Vision and Graphics. Human motion is often captured by inertial sensors (left), while the environment is mostly reconstructed using cameras (right). We integrate the two techniques together in EgoLocate (middle), a system that simultaneously performs human motion capture (mocap), localization, and mapping in real time from sparse body-mounted sensors, including 6 inertial measurement units (IMUs) and a monocular phone camera. On one hand, inertial mocap suffers from large translation drift due to the lack of the global positioning signal. EgoLocate leverages image-based simultaneous localization and mapping (SLAM) techniques to locate the human in the reconstructed scene. On the other hand, SLAM often fails when the visual feature is poor. EgoLocate involves inertial mocap to provide a strong prior for the camera motion. Experiments show that localization, a key challenge for both two fields, is largely improved by our technique, compared with the state of the art of the two fields.
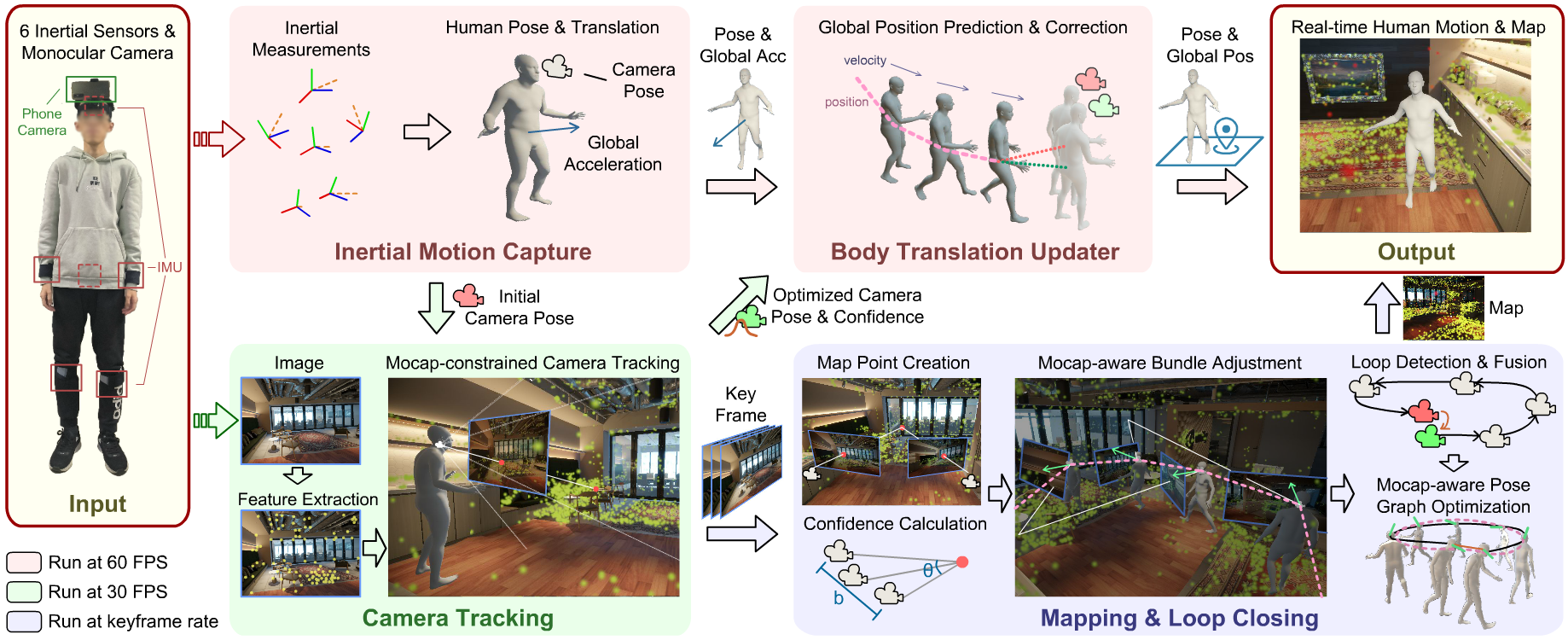
The inputs are real-time orientation and acceleration measurements of 6 IMUs and color images from a body-worn camera. We first estimate initial human poses and camera poses from sparse inertial signals (Inertial Motion Capture). Next, we refine the camera pose by minimizing the mocap constraints and the reprojection errors of the 3D-2D feature matches (Camera Tracking). Then, the refined camera pose and a confidence are used to correct the human’s global position and velocity (Body Translation Updater). This results in 60-FPS drift-free human motion output. In parallel, we perform mapping and loop closing using keyframes (Mapping & Loop Closing). We calculate another confidence for each map point, and use it in bundle adjustment (BA), where we jointly optimize the map points and the camera poses by a combined mocap and weighted reprojection error. If a loop is detected, we also perform pose graph optimization with mocap constraints. The estimated map is also outputted in real time.
Note:we use the ORB-SLAM3 viewer in this comparison. Due to randomness, the time and the global frame of each method may not be perfectly aligned.
This work was supported by the National Key R&D Program of China (2018YFA0704000), the NSFC (No.62021002), Beijing Natural Science Foundation (M22024), and the Key Research and Development Project of Tibet Autonomous Region (XZ202101ZY0019G). This work was also supported by THUIBCS, Tsinghua University, and BLBCI, Beijing Municipal Education Commission. This work was partially supported by the ERC consolidator grant 4DReply (770784). The authors would like to thank Wenbin Lin, Zunjie Zhu, Guofeng Zhang, and Haoyu Hu for their extensive help on the experiments and live demos. The authors would also like to thank Ting Shu, Shuyan Han, and Kelan Liu for their help on this project. Feng Xu is the corresponding author.
@article{EgoLocate2023,
author = {Yi, Xinyu and Zhou, Yuxiao and Habermann, Marc and Golyanik, Vladislav and Pan, Shaohua and Theobalt, Christian and Xu, Feng},
title = {EgoLocate: Real-time Motion Capture, Localization, and Mapping with Sparse Body-mounted Sensors},
journal={ACM Transactions on Graphics (TOG)},
year = {2023},
volume = {42},
number = {4},
numpages = {17},
articleno = {76},
publisher = {ACM}
}




